Introduction
It happens more often than anyone admits: a lab invests in a shiny AI model, hopes for disruptive insight—and then reality hits. The algorithm underwhelms. Results don’t generalize. The scientists get frustrated. Yet the underlying cause rarely gets the attention it deserves. It’s not that the model was wrong—it’s that the data feeding it wasn’t ready. In biotech, we obsess over model architectures, GPUs, and algorithms, while the foundation beneath them is quietly cracking. The real frontier isn’t the next big model—it’s data readiness. In this blog, I’ll walk through what data readiness really means, why it matters so deeply in biotech, and how Scispot provides the structure and discipline that make it possible.
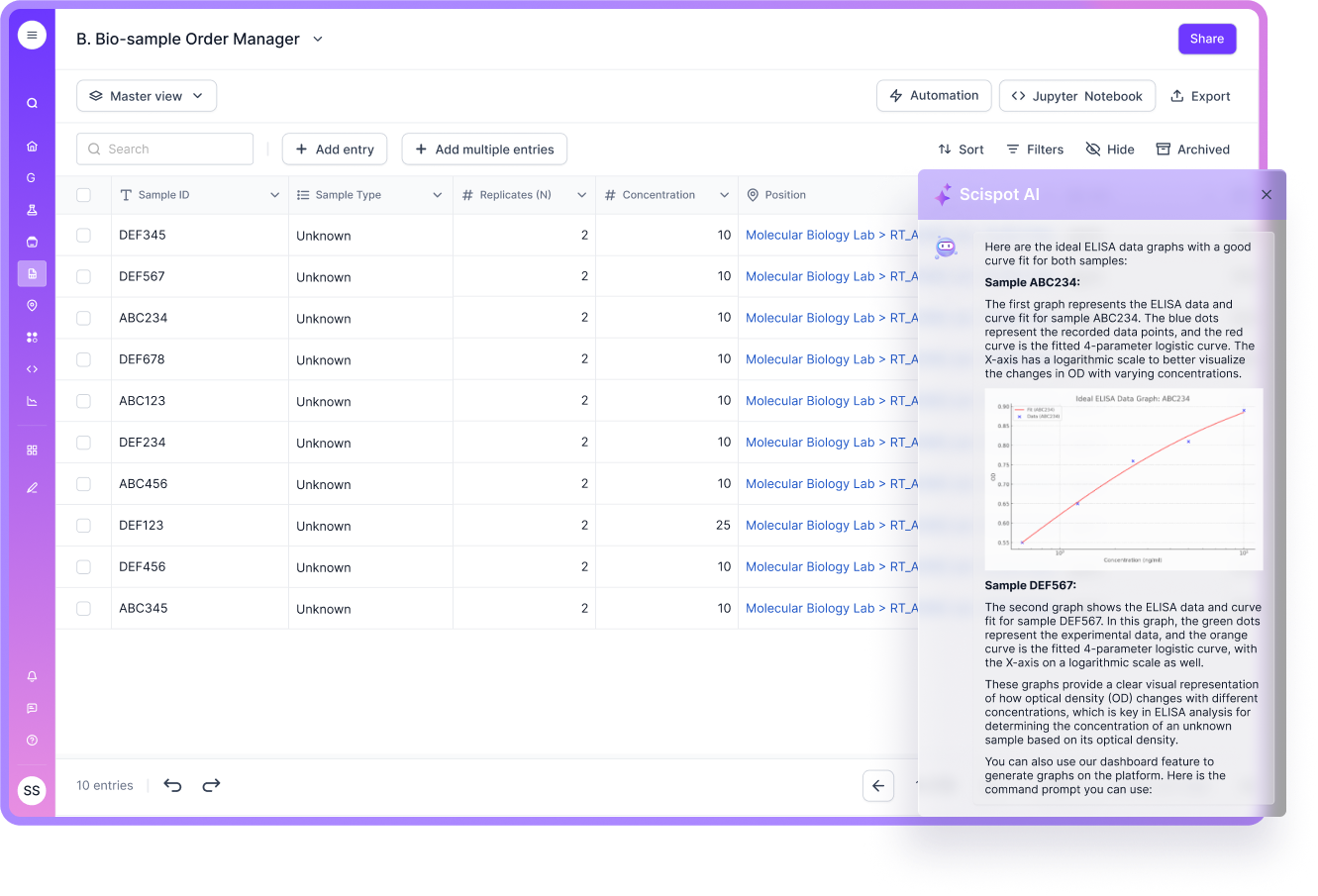
What is Data Readiness?
Data readiness goes beyond “we have data”. It’s about completeness (“did we capture all the fields we care about?”), conformity (“Are the types correct and standardized?”), consistency (“does the meaning hold across runs, times, and sites?”), lineage (“who, when, how was this created or modified?”) and timeliness (“is this fresh enough for decision‑making?”). If any one of these is weak, then downstream models, analyses, and decisions are compromised. In a biotech lab, the volume and complexity of data—from instruments, samples, protocols, omics, images—means these dimensions matter even more. Without readiness, you hamper innovation, create risk, and block scalability.
Why This Matters in Biotech
When you’re working on a biomarker, a cell therapy run, or a complex assay pipeline, sloppy data doesn’t just cost time—it costs credibility. As one industry whitepaper on AI in pharma and biotech highlights, “the main obstacle is poor data prep, not the models.” Systems that lack metadata, instrumentation lineage, or standardized formats struggle to turn data into decisions. Another insight: many labs believe they are “AI‑ready”, but surveys show a majority still struggle with data access, integration, and governance. When you’re racing to be first, speed is vital—but speed without structure often leads to re‑runs, surprise audits, and team burnout.
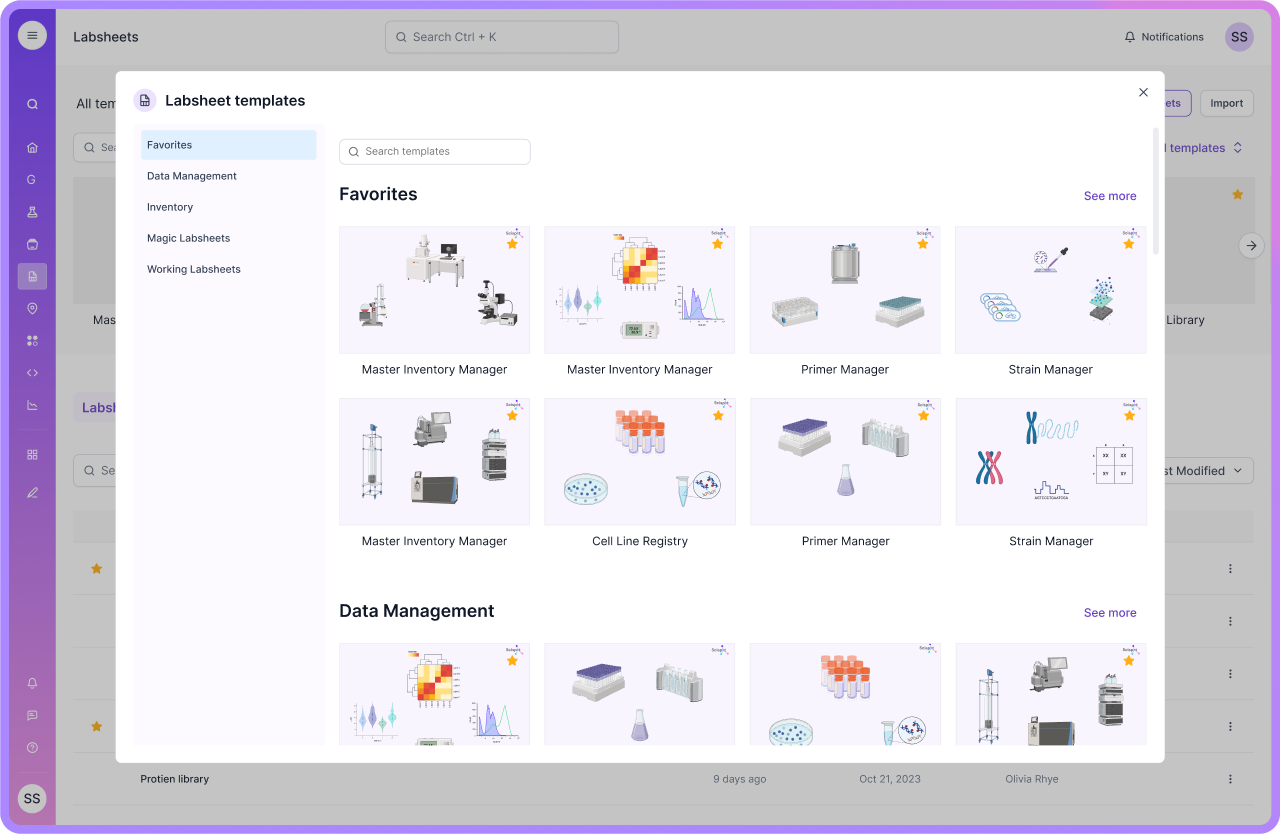
The Scispot Pattern for Data Readiness
At Scispot, we’ve seen that readiness is not a checkbox—it’s a pattern. Here’s how we help labs embed it:
First, we define typed Labsheets: for samples, runs, assays, instruments—every entity explicitly captured. Fields don’t float; they are typed and required as needed. Then we apply validation at ingest: the incoming data is checked for completeness, correct types, acceptable ranges, and required metadata. Next, we enrich with metadata: who captured it, when, instrument IDs, protocol versions, and lineage links. Then we link to entities: each sample is tied to a patient or batch ID; each run to an instrument; each result to a model version. And of course, we version everything—so if something changes, we know how and when. With this pattern, data isn’t just captured—it’s ready.
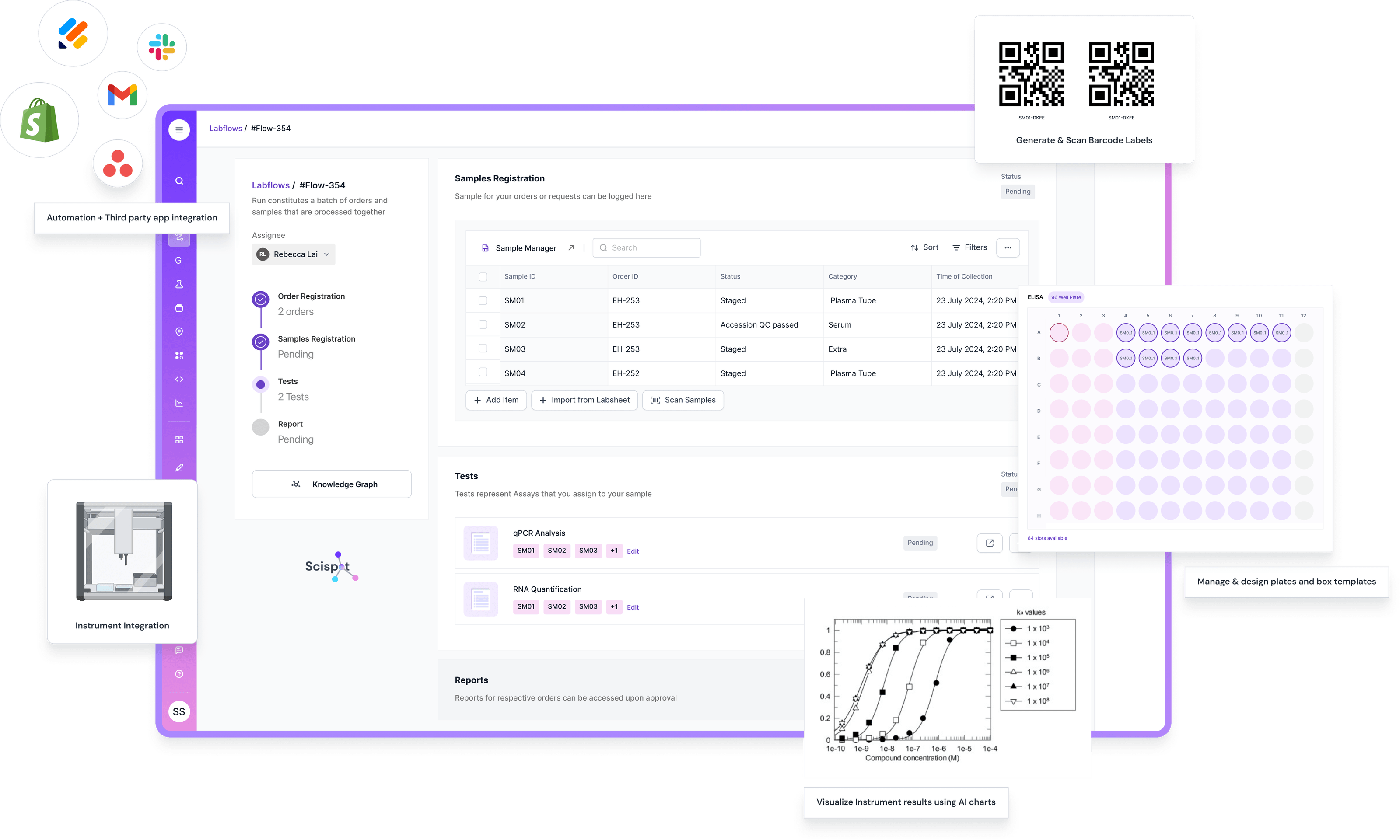
Analogy: Building on Solid Soil
You wouldn’t build a suspension bridge on soft, shifting ground. The engineers would refuse. And yet in our labs, we often do exactly that with data—we build our models and workflows on soft soil. If your data layer is unstable, every model, every insight, every decision is at risk of collapse. Data readiness is that soil work—it’s the unseen foundation that makes everything you do safe, reliable, and scalable.
The Playbook for Action
To operationalize data readiness in your lab, treat it like a project, not a side task. Start by listing your critical entities and fields—what absolutely must you capture? Then define rules and defaults: what fields are required, what types are allowed, what defaults apply when missing? Backfill missing fields: yes, it’s tedious, but you’ll thank yourself later. Add lineage hooks: capture who did what, when, and how. Finally, monitor the results with dashboards: what % of rows are valid? What’s the missingness per field? How fresh is the data? How reproducible are your runs?
Metrics That Matter
- % valid rows: out of all captured records, how many meet your rules?
- Missingness per field: which fields are consistently empty or defaulted?
- Freshness lag: how long between data capture and readiness for use?
- Reproducibility rate: how often can a result be traced back unambiguously to data + protocol?
When you track these, you start treating data readiness like a KPI—not a one‑off audit but a daily operating metric.
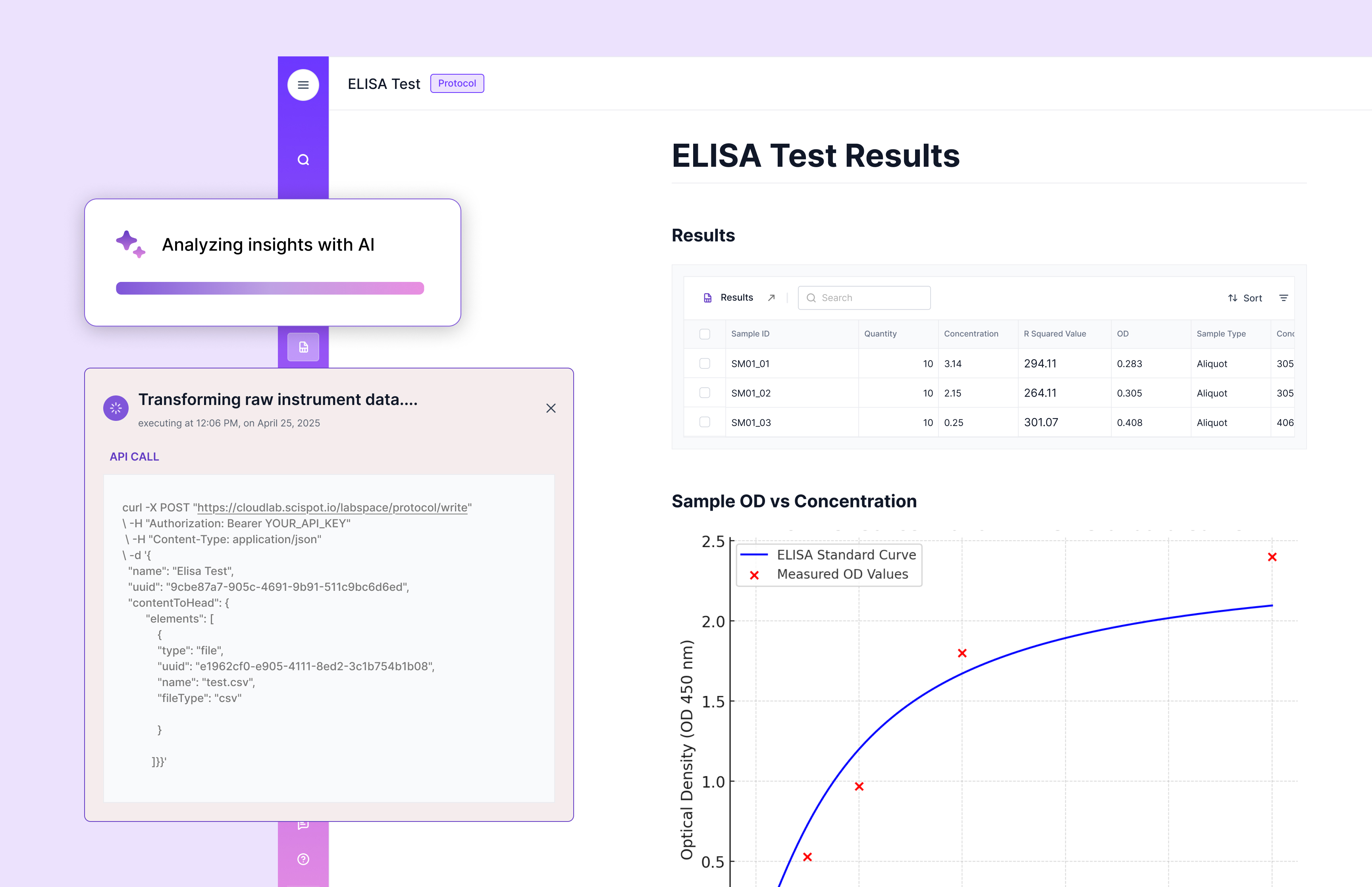
Pros and Cons
On the positive side: when you invest in readiness, you get better models, faster audits, fewer re‑runs, and a culture of trust. On the other side: upfront cleanup takes time. Some friction at capture time is inevitable (scientists need to fill required fields rather than free-text everything). There’s also the behavioral challenge—shifting from “just capture” to “capture well”.
Key Takeaways
Models are loud. Data readiness is quiet. But the quiet part wins. In biotech, your greatest competitive advantage isn’t merely having AI—it’s having ready data. If you codify your rules, track your progress like a KPI, and choose a platform built for readiness, you’ll leave the “data chaos” behind. At Scispot, we believe that labs that treat readiness as a first‑class citizen will be the ones who win.
Conclusion
If you’re still chasing models and ignoring your data foundation, you’re putting the cart before the horse. Data readiness is not optional—it’s essential. It’s the soil beneath your entire lab’s insight engine. When you lock it down—when you structure, validate, link, and version your data—you set the stage for speed, scale, and impact. And with tools like Scispot by your side, you don’t just hope for readiness—you build it.


.webp)
.webp)