.webp)
Scientific Data Management Systems: Boosting Research Efficiency
Scientific data management systems shape society in the same way that “clean plumbing” shapes a city. When data flows are reliable, research moves faster, errors drop, and outcomes improve.
At a societal level, these systems help labs turn raw instrument outputs into usable evidence. That evidence powers better medicines, safer food and water testing, and faster responses in outbreaks.
They also change who can participate in science. When data is easier to find, trace, and share, smaller labs and cross-border teams can contribute without reinventing the wheel.
What is a Scientific Data Management System?
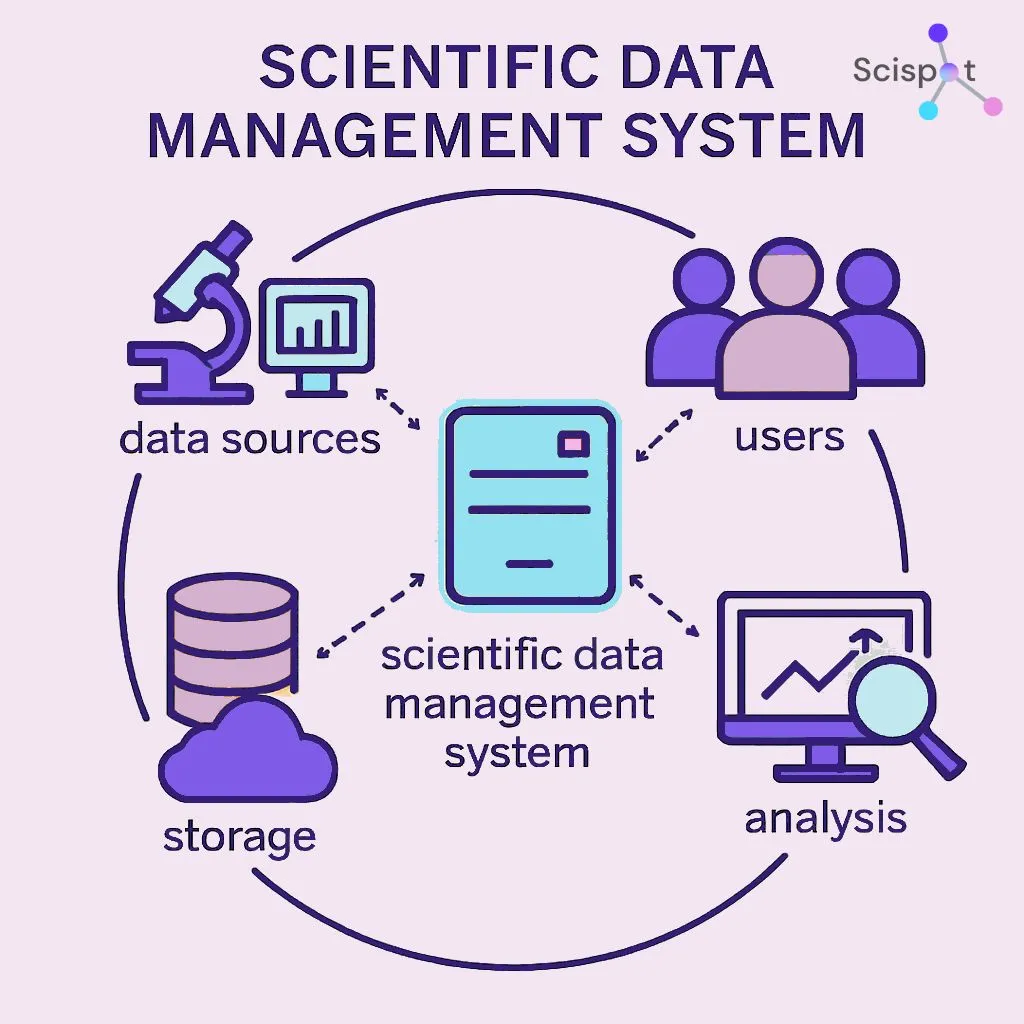
A Scientific Data Management System (SDMS) is the “source of truth” for scientific records. It stores raw files, processed results, and the context needed to trust them.
A modern SDMS does more than “save files.” It connects data to samples, methods, instruments, users, and approvals, so results stay explainable years later.
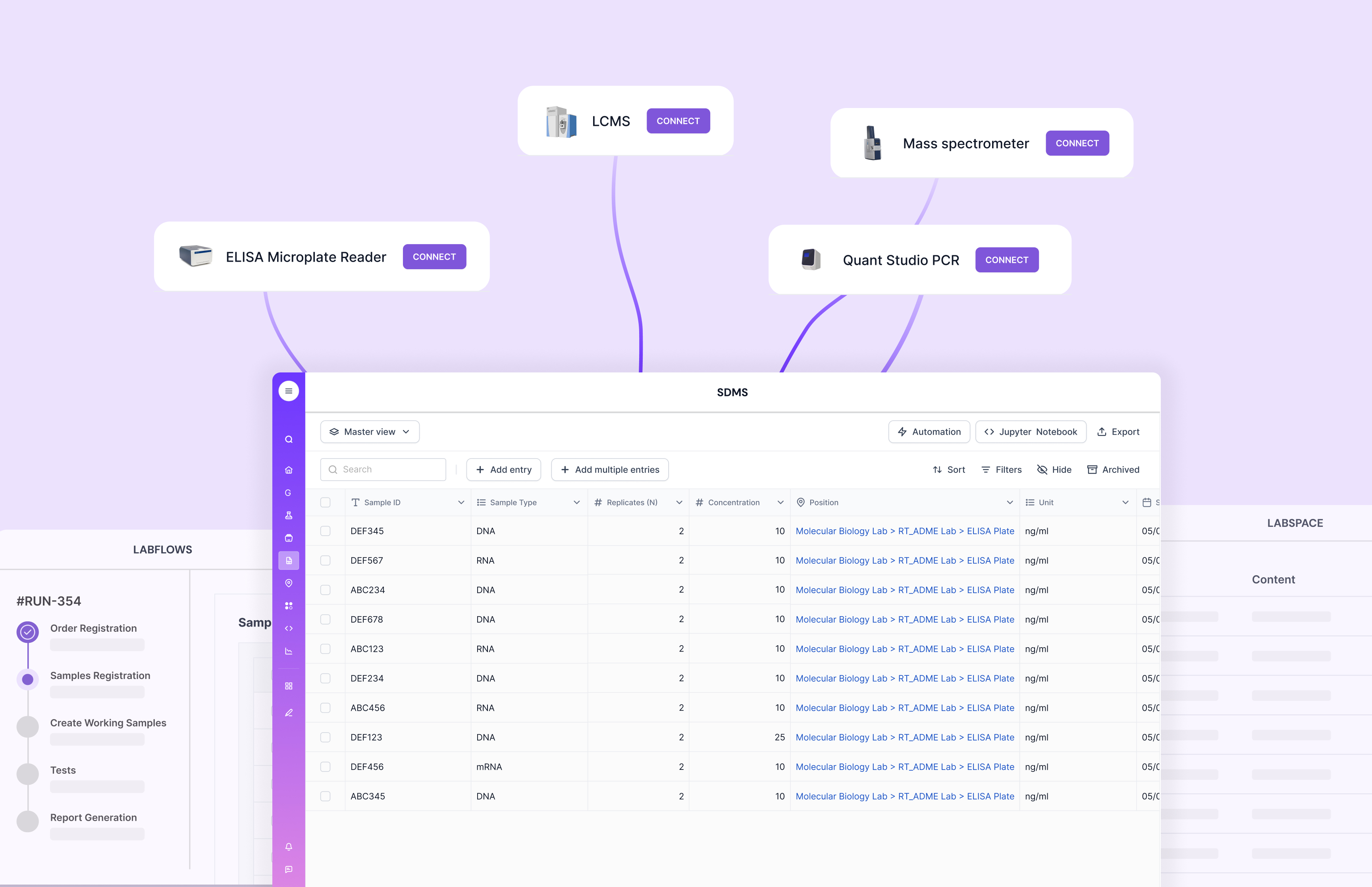
This is where Scispot stands out. Scispot works as a unified system where SDMS + LIMS-style traceability + workflow controls live together, so labs don’t have to stitch together separate tools to get end-to-end lineage.
Older setups often split these responsibilities across multiple products. That fragmentation can show up as weak search, slower audits, and more “export to Excel” workarounds that quietly reduce confidence over time.
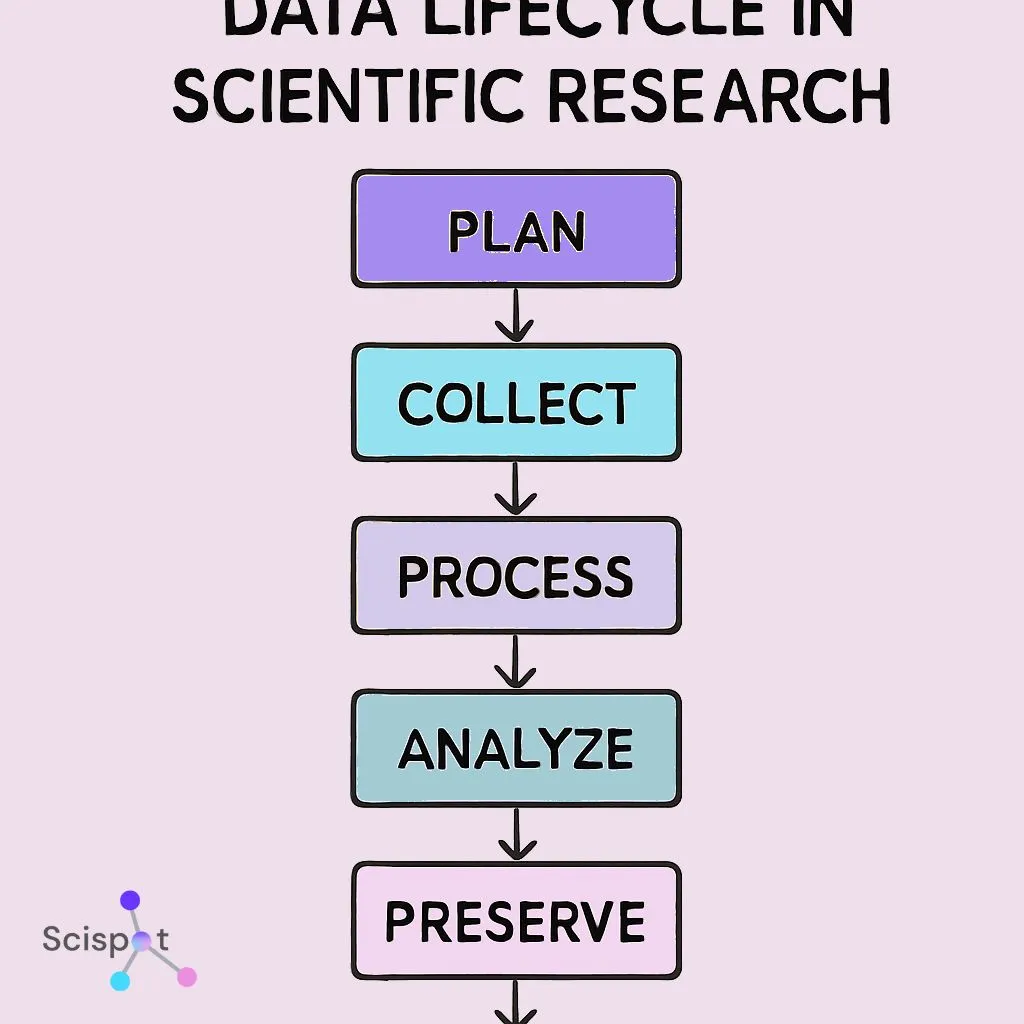
The data lifecycle in scientific research
The data lifecycle starts at creation and ends at archival. If any stage is shaky, the whole chain becomes harder to trust.
An SDMS supports each step: capture → validate → organize → analyze → retain. It reduces the “lost context” problem, where a file exists but no one remembers what it means.
Scispot’s advantage is continuity across the lifecycle. You can keep samples, results, raw files, and approvals in one connected model, instead of rebuilding context in each tool or folder.
Some legacy platforms can be very powerful, but the experience can vary by version and configuration. Even users reviewing established systems note gaps like older UI experiences or workflow friction, which matters when you’re trying to scale adoption across a whole lab.
Key features of scientific data management systems
A strong SDMS needs three things to create societal impact: traceability, usability, and interoperability. If any one is missing, teams either won’t adopt it, or they’ll keep side systems that undermine governance.
Traceability means you can answer “what changed, when, and why” without guesswork. That’s what protects reproducibility, patient safety, and public trust.
Usability determines whether the system becomes daily habit or “the place we upload things for compliance.” That difference decides whether data is truly reusable.
Interoperability decides whether your SDMS is a hub or a dead-end. When APIs, integrations, and structured schemas are first-class, labs can connect instruments, analysis notebooks, and downstream reporting without manual copy-paste.
Scispot is designed around that hub mindset. Instead of treating SDMS as a silo, it behaves like an operating layer that links data, workflow, and governance across teams.
Why Scispot Fits Modern Scientific Data Management
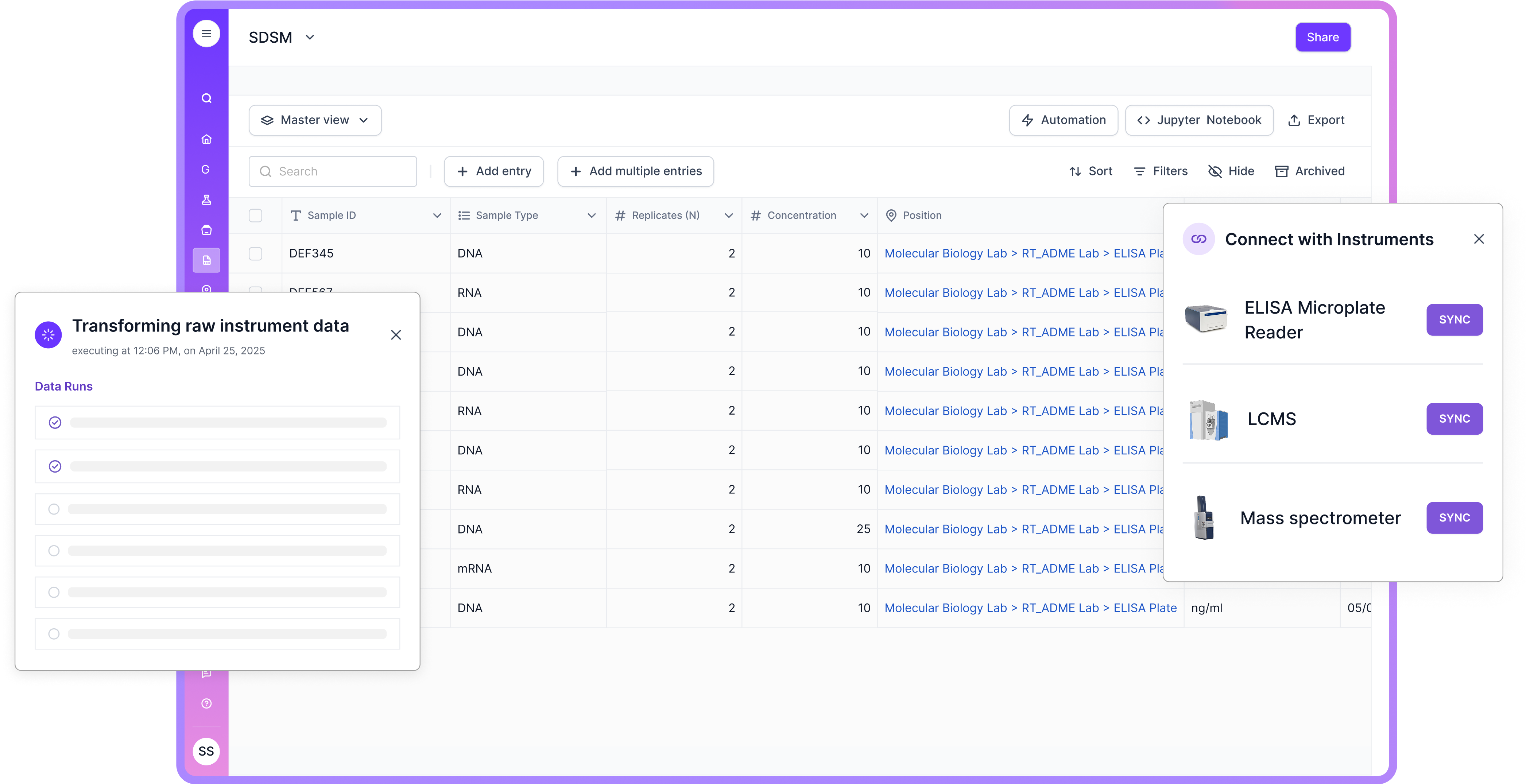
Scispot takes scientific data management beyond storage. It brings data creation, validation, analysis, and sharing into one connected system. That makes it easier for research teams to keep context intact across the full data lifecycle, instead of managing the same dataset in scattered tools.
Many SDMS products work mainly as repositories. Scispot is built to run day-to-day scientific workflows on top of your data. Structured tables, workflow steps, and integrations sit together, so teams spend less time cleaning, copying, and reconciling files. That reduces manual errors and supports stronger data integrity as volume and complexity grow.
Scispot also helps teams tighten governance without slowing down research. Audit trails, access controls, and review flows can live inside the same place where work happens. This makes compliance feel less like an extra task and more like a default habit, while still making it simple to share data with collaborators and support reproducible science.
Ensuring data integrity and governance
Integrity is the foundation of credible science. Governance is how you keep integrity consistent as teams grow. Regulated environments often anchor these expectations in requirements like secure, time-stamped audit trails for electronic records.
That’s not just policy language. It’s the practical difference between “we think this is right” and “we can prove it.”
Scispot’s strength is making governance feel like a natural part of work. Approvals, reviews, permissions, and traceability can be built into the workflow, instead of bolted on after the fact.
In contrast, many legacy LIMS/SDMS deployments drift into heavy customization to match real lab processes. Users themselves flag the risk of becoming “too customized,” which can make upgrades and consistency harder later.
Data curation, organization, and storage
Curation is active stewardship. It’s the difference between a library and a storage locker. Good organization prevents “data debt.” Data debt is like technical debt, but for science: you pay later with rework, delays, and repeated experiments.
Scispot supports curation by keeping structured records linked to the raw evidence. That linkage is what makes later reuse realistic, especially when people leave, teams change, or partners audit your work.
Some tools still push teams toward exports for statistics or reporting workflows. When that happens, the real “system of record” becomes a spreadsheet trail, which is fragile and hard to govern.
.jpeg)
Scientific data analysis and visualization
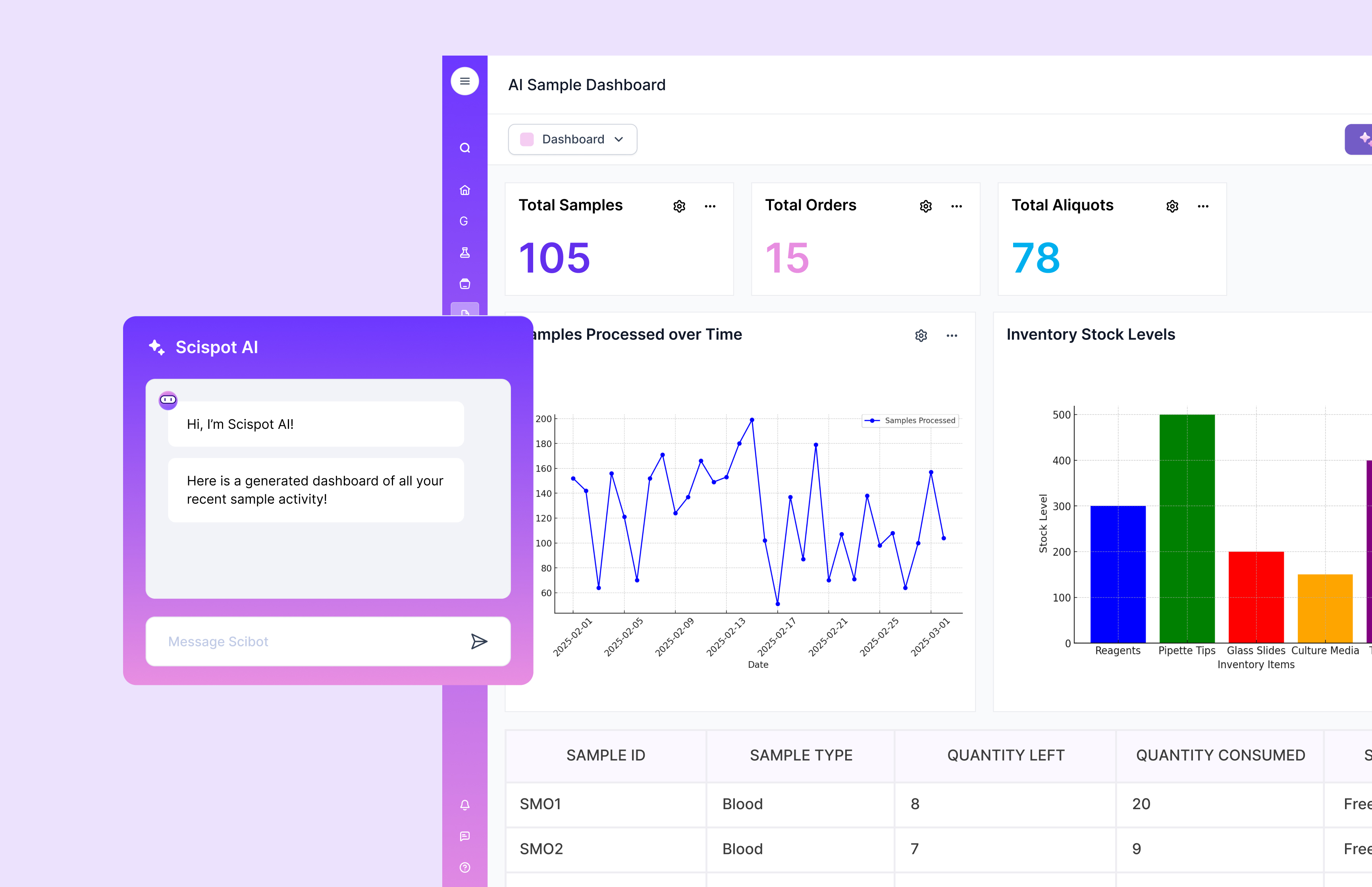
Analysis is where data becomes decisions. Visualization is how teams align on what the data is saying. A modern platform should reduce the gap between “data captured” and “insight shared.” If it takes too many steps to get plots, QC views, and summaries, labs end up building parallel dashboards elsewhere.
Scispot’s approach fits here because analysis outputs can stay connected to the underlying records. That improves auditability and speeds up collaboration, since reviewers can trace a chart back to the exact source data and context.
Facilitating data sharing and collaboration
Sharing is a force multiplier for science. But sharing without context can be worse than not sharing at all. SDMS tools help collaboration by packaging context with the data. That supports reproducibility and reduces misinterpretation across teams.
Scispot enables collaboration through structured linking and controlled access. That means partners can see what they need, without exposing sensitive details or losing governance.
Societal impact of scientific data management systems
When scientific data systems work well, society benefits in concrete ways. Results become more trustworthy, research cycles shorten, and crises become easier to respond to.
Public trust rises when studies are reproducible. That trust matters for vaccines, clinical research, environmental monitoring, and food safety.
Better systems also democratize innovation. When workflows are easier to run and data is easier to reuse, smaller teams can compete with bigger budgets.
Scispot contributes to this impact by making “good science hygiene” easier to do daily. It turns traceability, governance, and reuse into default behavior, not a special project.
The future of scientific data management
The next wave is automation plus AI. But the real unlock is not flashy prediction. It is clean, connected, governed data.
AI is like a sports car. Without good roads, you still don’t get anywhere fast.
Future-ready labs will pick platforms that keep data structured, traceable, and integration-ready from day one. That is exactly where Scispot is positioned: as the system that keeps data usable for humans today and for automation tomorrow.

.webp)
.webp)